时隔一年再看线程池,这次主要是设计一个串行任务队列,以满足在多线程环境下串行执行任务的需求。
如果线程池中只有一个大队列,那么在不断向队列中提交任务,工作线程从队列中取任务执行的过程中,没法保证先入队的任务能先被执行完成,此时就需要引入串行队列。
我们的期望是串行队列中的任务按照入队顺序执行,即该队列中同一时间只能有一个任务被执行,该任务执行完成后才能执行队列中后续的任务。
要怎么实现这一点呢?其实很简单,在任务执行完成后执行队列中的回调,告知队列向线程池的队列中添加任务即可,看图:
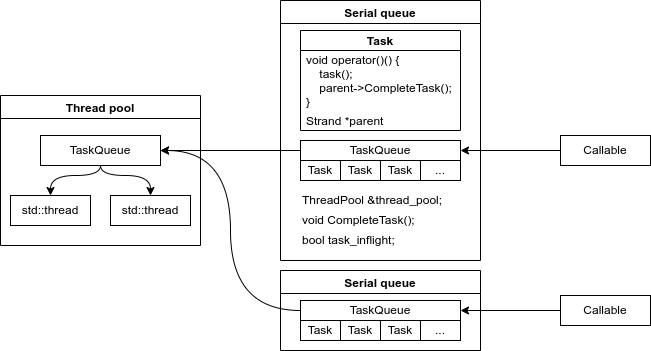
SerialQueue 类中封装了 Task 类,创建 Task 类时带入所属串行队列的指针用于执行回调函数。让我们把重点放在 Task 类上,队列由用户添加可执行对象 Callable 和 Task 对象驱动,Callable 到达串行队列时被封装为 Task 对象,根据串行队列的 task_inflight 变量来确定是进入串行队列的 TaskQueue 还是直接进入 ThreadPool 的 TaskQueue。Task 在 ThreadPool 中被执行完毕后执行回调函数,如果所属的串行队列中有其他任务,则继续将任务加入 ThreadPool 中执行,否则将 task_inflight 置为 false,等待新的任务入队。
还是直接看代码实现利于理解,下面是 SerialQueue 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
class SerialQueue {
class Task {
public:
Task() {}
Task(SerialQueue *parent, std::function<void()> func)
: parent_(parent), func_(func) {}
// rule of zero
void operator()() {
func_();
parent_->task_complete();
}
private:
SerialQueue *parent_;
std::function<void()> func_;
};
public:
SerialQueue(ThreadPool &thread_pool,
const std::string &queue_name = "default")
: thread_pool_(thread_pool), queue_name_(queue_name) {}
// rule of five
~SerialQueue() = default;
SerialQueue(const SerialQueue &) = delete;
SerialQueue &operator=(const SerialQueue &) = delete;
SerialQueue(SerialQueue &&) = delete;
SerialQueue &operator=(SerialQueue &&) = delete;
template <typename F, typename... Args>
auto submit(F &&f, Args &&...args)
-> std::future<typename std::invoke_result<F, Args...>::type> {
using ResultType = typename std::invoke_result<F, Args...>::type;
auto func = std::bind(std::forward<F>(f), std::forward<Args>(args)...);
auto task_ptr = std::make_shared<std::packaged_task<ResultType()>>(func);
std::function<void()> task_warpper = [task_ptr]() { (*task_ptr)(); };
Task task{this, std::move(task_warpper)};
{
std::unique_lock<std::mutex> lock(queue_mutex_);
if (task_inflight_) {
task_queue_.push(std::move(task));
} else {
task_inflight_ = true;
thread_pool_.submit_impl(std::move(task));
}
}
return std::move(task_ptr->get_future());
}
std::string name() { return queue_name_; }
private:
void task_complete() {
Task task;
{
std::unique_lock<std::mutex> lock(queue_mutex_);
if (task_queue_.empty()) {
task_inflight_ = false;
return;
}
task = std::move(task_queue_.front());
task_queue_.pop();
}
thread_pool_.submit_impl(std::move(task));
}
private:
ThreadPool &thread_pool_;
std::string queue_name_;
bool task_inflight_ = false; // thread-safe
std::queue<Task> task_queue_;
std::mutex queue_mutex_;
};
|
关于 The rule of three/five/zero:
- rule of zero:尽量避免显式定义特殊成员函数,依赖标准库的工具来管理资源。
- rule of five:如果需要显式定义析构函数、拷贝构造函数、拷贝赋值运算符、移动构造函数或移动赋值运算符中的任何一个,那么通常也需要显式定义其他四个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
class ThreadPool {
public:
ThreadPool() {
for (int i = 0; i < thread_num_; ++i) {
threads_.emplace_back([&]() {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(queue_mutex_);
queue_condition_.wait(
lock, [&]() { return stop_ || !task_queue_.empty(); });
if (stop_ && task_queue_.empty()) {
break;
}
task = std::move(task_queue_.front());
task_queue_.pop();
}
task();
}
});
}
}
~ThreadPool() { wait_and_stop(); }
// rule of five
ThreadPool(const ThreadPool &) = delete;
ThreadPool &operator=(const ThreadPool &) = delete;
ThreadPool(ThreadPool &&) = delete;
ThreadPool &operator=(ThreadPool &&) = delete;
template <typename F, typename... Args>
auto submit(F &&f, Args &&...args)
-> std::future<typename std::invoke_result<F, Args...>::type> {
using ResultType = typename std::invoke_result<F, Args...>::type;
auto func = std::bind(std::forward<F>(f), std::forward<Args>(args)...);
auto task_ptr = std::make_shared<std::packaged_task<ResultType()>>(func);
std::function<void()> task_warpper = [task_ptr]() { (*task_ptr)(); };
submit_impl(std::move(task_warpper));
return std::move(task_ptr->get_future());
}
void submit_impl(std::function<void()> task) {
{
std::unique_lock<std::mutex> lock(queue_mutex_);
task_queue_.push(std::move(task));
}
queue_condition_.notify_one();
}
void wait_and_stop() {
if (stop_) {
return;
}
stop_ = true;
queue_condition_.notify_all();
for (auto &thread : threads_) {
thread.join();
}
threads_.clear();
threads_.shrink_to_fit();
}
private:
bool stop_ = false;
int thread_num_ = std::thread::hardware_concurrency();
std::vector<std::thread> threads_;
std::queue<std::function<void()>> task_queue_;
std::mutex queue_mutex_;
std::condition_variable queue_condition_;
};
|
- LLVM: include/llvm/Support/TaskQueue.h Source File
- LLVM: lib/Support/ThreadPool.cpp Source File